简答与编程
- 含有 n 个结点的 3 叉树的最小高度是多少?
Log3(2n+1) 向上取整 - 已知一棵度为 4 的树中,其度为 0,1,2,3,的结点数分别为 14,4,3,2。求该树的结点总数 n 和度为 4 的结点个数 n-23,并给出推导过程。
度数之和=4+6+6+4x=16+4(n-23)
结点数=度数之和 +1=17+4(n-23)=n
àn=25
度为 4 的节点个数=n-14-4-3-2=2
3. 一棵有 n 个结点的满二叉树有多少个分支结点和多少个叶子结点?该满二叉树的高度是多少?
叶子:(n+1) / 2
分支:n-(n+1)/2=(n-1)/2
Log(n+1)
3:2 1 2
7:4 3
4. 已知完全二叉树的第 8 层有 10 个节点,则其分支结点数是多少?(请给出求解过程)
第七层有:64 个结点,其中 59 个为叶子结点.
总共 59+10=69 个叶子节点
分支节点=n- 叶子节点=2^8-1+10-69=68
- 已知一棵完全二叉树共有 1000 个节点,试求:(要求写出求解过程)
(1) 树的高度;
(2) 叶子节点数:
(3) 单支节点数;
(4) 最后一个非终端节点的序号(默认根结点的编号为 1)。
高度: [Logn] 向下取整 +1=10
最后一层叶子节点:1000-511=489
倒数第二层叶子节点:256-(489+1)/2=6
叶子节点:489+6=495
单分子结点数:1
250
6. 设一棵完全二叉树有 80 个结点,则在该二叉树中的叶子结点数为多少?给出分析过程。
高度:log(n) 向下取整 +1=7
最后一层叶子节点个数:80-2^6+1=17
倒数第二层叶子节点:2**5-(17+1)/2=23
叶子节点:=17+23=40
7. 对于哈夫曼树,回答下列问题:(要求写出求解过程)
(1) 若一课哈夫曼树的叶子节点个数为 6,则该树的总节点个数为多少?
(2) 以数据集合{2,5,7,10,16}为权值构造一棵哈夫曼树,其带权路径长度为多少?
6+(6-1)=11
16*1+7*2+(5+2)*3=51
8. 对给定的数列 R={7,16,4,8,20,9,6,18,5},求解以下问题:(要求写出求解过程)
(1) 构造一棵二叉排序树:
(2) 给出按中序遍历得到的数列 R1
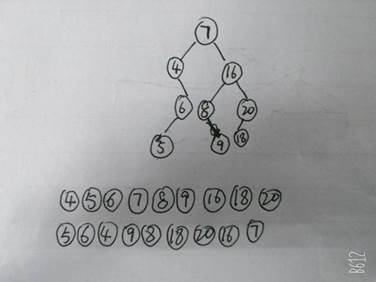
(3) 给出按后序遍历得到的数列 R2。
- 为什么提出 AVL 树?分析 AVL 树的平均比较次数。
在含有 n 个结点的二叉排序树中查找操作的执行时间与树形有关,在最坏情况下执行时间为 O(n),为了避免这种情况.
设 N(h) 为 T 的结点数:
N(1)=1,N(2)=2,N(h)=N(h-1)+N(h-2)+1
由此得到 N(h) 约等于 2^h-1,
即 log(N(h)+1)=h
所所以含有 n 个结点的平衡二叉树的平均查找长度 O(logn)
10. 在单链表和双链表中,能否从当前节点出发访问到任一节点?为什么?
单链表不能,因为单链表每个结点只有后指针指向下一个结点,不能指向前一个结点.但双链表既有指向后一个结点的制指针,又有指向后一个结点的指针.
11. 试各举一个实例,简要说明栈和队列在程序设计中所起的作用。
队列: 在排队打水的时候既要保持效率最大又要保持先到先得,就需要使用队列,哪一个打水器使用完成就从队列中选第一个人去打水.用于将散乱的数据按照一定规律排列,同时保持良好的先后顺序.
栈: 在生活中,有一个大箱子,而你会将最近经常穿的物品比如衣服放在最上面,而不常用的衣服放在最下面.栈就是临时存放最近的东西.
12. 请描述对于线性表的顺序存储和链式存储结构的优缺点。举例说明在什么样的情况下选用顺序存储,什么情况下选用链式结构存储?
顺序存储: 优点: 易于查找和修改,缺点: 插入或者删除的时候不方便,存储空间利率低
链式存储: 优点: 插入或删除元素很方便,使用灵活,存储空间利用高.
缺点: 查找和修改需要遍历整个链表.
在经常查找和修改的时候使用顺序表.
在经常插入或者删除的时候使用链表.
13. 线性表以链式结构进行存储,如果想从当前结点出发访问到任一结点,该链式结构最好是采用何种存储方案?为什么?
双链表,单链表只能访问后一结点,不能访问前面的结点,但双链表都可以
循环单链表
14. 链表中头结点的作用是什么?
使得在链表头部的操作 (如: 插入删除等) 与在链表中部与尾部一致 (统一)
使非空链表与空链表的操作统一
15. 请分析在顺序查找及折半查找中,若以元素查找等概论计算,这两种查找方案各自的 ASL 为多少?给出结论及求解过程。
顺序查找: (1+2+3+…+n)/n=(n+1)/2
折半查找: (1*1+2*2+4*3+8*4+…+(2^(n-1)*n))/n=logn 向下取整 +1
16. 在直接插入排序、希尔排序、冒泡排序、简单选择排序、快速排序、堆排序和基数排序方法中:
- 平均时间复杂度为 O(n2)的有哪些?
直接插入 冒泡 简单选择 - 平均时间复杂度为 O(nlog2n)的有哪些?
快速排序 堆排序 - 给出关键字序列{4,7,1,2,8,3}的直接插入排序过程。
4 7 1 2 8 3 第一遍操作 7
1 4 7 2 8 3 第二遍操作 1
1 2 4 7 8 3 第三遍操作 2
1 2 4 7 8 3 第四遍操作 8
1 2 3 4 7 8 第五遍操作 3
18. 给出关键字序列{30,15,28,70,50,80,7,80,30,10}的希尔排序过程,取增量序列为 d={5,3,1},排序结果为升序排列。
30,15,28,70,50,80,7,80,30,10
30 7 28 30 10 80 15 80 70 50
15 7 28 30 10 70 30 80 80 50
7 10 15 28 30 30 50 70 80 80
结构体:
请写出线性表的顺序存储结构 --- 顺序表的结构体
typedef struct
{
ElemType data[Maxsize];//存放线性表中的元素
int length;//存放线性表的长度
}SqList;//顺序表类型
请写出线性表的链式存储结构 --- 单链表的结构体
typedef struct Lnode
{
ElemType data;//存放元素值
struct LNode *next;//指向后继节点
}LinkNode;//单链表节点类型
请写出线性表的链式存储结构 --- 双链表的结构体
typedef struct DNode
{
ElemType data;//存放元素值
struct DNode *prior;//指向前驱节点
struct DNode *next;//指向后继节点
}DLinkNode;//双链表的节点类型
请写出顺序栈的结构体
typedef struct
{
ElemType data[Maxsize];//存放栈中的数据元素
int top;//栈顶指针,既存放栈顶元素在 data 数组中的下标
}SqStack;//顺序栈类型
请写出链栈的结构体
typedef struct linknode
{
ElemType data;//数据域
struct linknode *next;//指针域
}LinkNode;//链栈节点类型
请写出顺序队的结构体
typedef struct
{
ElemType data[Maxsize];//存放队中元素
int font,rear;//队头和队尾指针
}SqQueue;//顺序队类型
请写出链队的结构体
typedef struct Qnode
{
ElemType data; //存放元素
struct Qnode *next; //下一个节点指针
}QNode; //链队数据节点的类型
请写出二叉树的链式存储的结构体
Typedef struct node
{
ElemType data; //数据元素
struct node *lchild; //指向左孩子结点
struct node *rchild; //指向右孩子结点
}BTNode;
图的邻接矩阵
Typedef struct
{
Int no;
Info Type info
}VertexType;
Typedef struct
{
Int edges[maxv][maxv];
Int n,e;
Vertextype vex[maxv];
}matgraph;
排序:
void GetData(RecType *& R,int n)
{
srand(time(0));
R = (RecType*)malloc(sizeof(RecType)*n);
int i;
for(i=0;i<n;i++)
{
R[i].key=rand();
}
printf(" 生成了%d 条记录\n",n);
}
//直接插入排序
void InsertSort(RecType R[],int n) //对 R[0..n-1] 按递增有序直接插入排序
{
int i,j;
RecType tmp;
for (i=1; i<n; i++)
{
tmp=R[i];
j=i-1; //从右向左在有序区 R[0..i-1] 中找 R[i] 的插入位置
while (j>=0 && tmp.key<R[j].key)
{
R[j+1]=R[j]; //将关键字大于 R[i].key 的记录后移
j--;
}
R[j+1]=tmp; //在 j+1 处插入 R[i]
}
}
//end
//希尔排序
void ShellSort(RecType R[],int n) //希尔排序算法
{
int i,j,gap;
RecType tmp;
gap=n/2; //增量置初值
while (gap>0)
{
for (i=gap; i<n; i++) //对所有相隔 gap 位置的所有元素组进行排序
{
tmp=R[i];
j=i-gap;
while (j>=0 && tmp.key<R[j].key)//对相隔 gap 位置的元素组进行排序
{
R[j+gap]=R[j];
j=j-gap;
}
R[j+gap]=tmp;
j=j-gap;
}
gap=gap/2; //减小增量
}
}
//end
//冒泡排序
void BubbleSort(RecType R[],int n)
{
int i,j,k,exchange;
RecType tmp;
for (i=0; i<n-1; i++)
{
exchange=0;
for (j=n-1; j>i; j--) //比较,找出最小关键字的记录
if (R[j].key<R[j-1].key)
{
tmp=R[j]; //R[j] 与 R[j-1] 进行交换,将最小关键字记录前移
R[j]=R[j-1];
R[j-1]=tmp;
exchange=1;
}
/**
printf("i=%d: ",i);
for (k=0; k<n; k++)
printf("%d ",R[k].key);
printf("\n");
**/
if (exchange==0) //中途结束算法
return;
}
}
//end
//快速排序
void QuickSort1(RecType R[],int s,int t) //对 R[s] 至 R[t] 的元素进行快速排序
{
int i=s,j=t;
RecType tmp;
if (s<t) //区间内至少存在两个元素的情况
{
tmp=R[s]; //用区间的第 1 个记录作为基准
while (i!=j) //从区间两端交替向中间扫描,直至 i=j 为止
{
while (j>i && R[j].key>=tmp.key)
j--; //从右向左扫描,找第 1 个小于 tmp.key 的 R[j]
R[i]=R[j]; //找到这样的 R[j],R[i]"R[j] 交换
while (i<j && R[i].key<=tmp.key)
i++; //从左向右扫描,找第 1 个大于 tmp.key 的记录 R[i]
R[j]=R[i]; //找到这样的 R[i],R[i]"R[j] 交换
}
R[i]=tmp;
QuickSort1(R,s,i-1); //对左区间递归排序
QuickSort1(R,i+1,t); //对右区间递归排序
}
}
void QuickSort(RecType R[],int n)
{
QuickSort1(R, 0, n-1);
}
//end
//堆排序
//调整堆
void sift(RecType R[],int low,int high)
{
int i=low,j=2*i; //R[j] 是 R[i] 的左孩子
RecType temp=R[i];
while (j<=high)
{
if (j<high && R[j].key<R[j+1].key) //若右孩子较大,把 j 指向右孩子
j++; //变为 2i+1
if (temp.key<R[j].key)
{
R[i]=R[j]; //将 R[j] 调整到双亲结点位置上
i=j; //修改 i 和 j 值,以便继续向下筛选
j=2*i;
}
else break; //筛选结束
}
R[i]=temp; //被筛选结点的值放入最终位置
}
//堆排序
void HeapSort(RecType R[],int n)
{
int i;
RecType temp;
for (i=n/2; i>=1; i--) //循环建立初始堆
sift(R,i,n);
for (i=n; i>=2; i--) //进行 n-1 次循环,完成推排序
{
temp=R[1]; //将第一个元素同当前区间内 R[1] 对换
R[1]=R[i];
R[i]=temp;
sift(R,1,i-1); //筛选 R[1] 结点,得到 i-1 个结点的堆
}
}
//end
//归并排序
void Merge(RecType R[],int low,int mid,int high)
{
RecType *R1;
int i=low,j=mid+1,k=0; //k 是 R1 的下标,i、j 分别为第 1、2 段的下标
R1=(RecType *)malloc((high-low+1)*sizeof(RecType)); //动态分配空间
while (i<=mid && j<=high) //在第 1 段和第 2 段均未扫描完时循环
if (R[i].key<=R[j].key) //将第 1 段中的记录放入 R1 中
{
R1[k]=R[i];
i++;
k++;
}
else //将第 2 段中的记录放入 R1 中
{
R1[k]=R[j];
j++;
k++;
}
while (i<=mid) //将第 1 段余下部分复制到 R1
{
R1[k]=R[i];
i++;
k++;
}
while (j<=high) //将第 2 段余下部分复制到 R1
{
R1[k]=R[j];
j++;
k++;
}
for (k=0,i=low; i<=high; k++,i++) //将 R1 复制回 R 中
R[i]=R1[k];
}
void MergePass(RecType R[],int length,int n) //对整个数序进行一趟归并
{
int i;
for (i=0; i+2*length-1<n; i=i+2*length) //归并 length 长的两相邻子表
Merge(R,i,i+length-1,i+2*length-1);
if (i+length-1<n) //余下两个子表,后者长度小于 length
Merge(R,i,i+length-1,n-1); //归并这两个子表
}
void MergeSort(RecType R[],int n) //自底向上的二路归并算法
{
int length;
for (length=1; length<n; length=2*length) //进行 log2n 趟归并
MergePass(R,length,n);
}
//end
问答题:
- 已知一棵完全二叉树共有 n 个节点,试求:(要求写出求解过程)
(1) 树的高度;
(2) 叶子节点数:
(3) 单支节点数;
(4) 第 3 层第 3 个结点的编号,以及它的孩子结点的编号为什么?(默认根结点的编号为 1)。
- 在利用链式结构(单链表、双链表、单循环链表及双循环链表)进行数据的访问中,能否从当前节点出发访问到任一节点?为什么?请给出你的分析的理由,描述出单、双链表的结构及对应的循环链表的特点。
- 请分析在顺序查找、折半查找、分块查找中,若查找元素时以等概论计算,这些查找方案各自的 ASL 为多少?给出结论及求解过程。
- 对于 n 个顶点的无向图和有向图(均为不带权图),当采用邻接矩阵和邻接表表示时,如何求解以下问题:
(1) 图中有多少条边;
(2) 任意两个顶点之间 i 和 j 是否有边相连;
(3) 任意一个顶点的度是多少。
5. 一棵满二叉树,若是操作仅限于进行元素的查找(包括查找孩子结点、双亲结点、兄弟结点),最佳的存储方案是?说明理由。
6. 在直接插入排序、希尔排序、冒泡排序、简单选择排序、快速排序、堆排序和基数排序方法中
(1) 不需要进行关键字比较的是哪些?
(2) 关键字比较的次数与记录的初始排列次序无关的是哪些?
(3) 上面各种排序算法的平均时间效率分别为什么?
7. 将一个顺序表中所有的元素实现逆置,算法的空间复杂度尽量保持为 O(1),请用文字描述出你的方案。
含有 n 个结点的 3 叉树的最小高度是多少?
8. 已知完全二叉树的第 8 层有 8 个节点,则其分支结点数是多少?(请给出求解过程)
9. 请描述对于线性表的顺序存储和链式存储结构的优缺点。举例说明在什么样的情况下选用顺序存储,什么情况下选用链式结构存储?
10. 试各举一个实例,简要说明栈和队列在程序设计中所起的作用。
编程题:
- 能写出顺序表、单链表、双链表、单循环链表、双循环链表、顺序栈、顺序队、链栈、链队的结构体。
- 写出折半查找的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
- 写出分块查找的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
- 写出直接插入排序的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
- 写出冒泡排序的改进算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
- 写出希尔排序的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。